Transformer les caméras en capteurs de données pour la mobilité
le Deep Learning à l’épreuve du terrain
- Matthias Houllier
La vidéo au service de la mobilité
La vision par ordinateur est une discipline de l’IA qui consiste à analyser, traiter et comprendre automatiquement des images. Jusqu’à très récemment, les avancées technologiques dans le domaine étaient limitées. Les algorithmes manquaient de flexibilité et étaient très sensibles aux variations contextuelles (luminosité, angle de vue, distance). Les applications nécessitaient une ingénierie lourde et des algorithmes d’analyses de pixels sur-mesure. Par conséquent, seuls quelques cas d’usage étaient suffisamment robustes pour être utilisés à grande échelle. Dans la mobilité, seule la lecture automatique de plaque d’immatriculation s’est largement répandue. Pour les autres applications, la grande majorité des images restait alors traitée manuellement, avec un déficit de ressources humaines et financières pour en exploiter le plein potentiel.
Mais le Deep Learning a tout changé. En 2015, le réseau de neurones convolutif ResNet (erreur de 3.6%*) permet pour la première fois de dépasser l’erreur humaine estimée à environ 5% au concours de classification ImageNet (compétition mondiale de référence en vision par ordinateur).
S’ensuit alors un nouvel engouement autour de l’analyse automatique de vidéos. La caméra apparait potentiellement comme le capteur ultime permettant d’alimenter les gestionnaires de mobilité en données fines, fiables et disponibles à grande échelle pour toute une série d’initiatives de fluidification :
Détecter le nombre de personnes à l’intérieur des véhicules pour mettre en place des politiques en faveur des covoitureurs (voies dédiées, tarifs préférentiels sur autoroutes ou parkings, etc.)
Détecter les places de stationnement disponibles pour guider les automobilistes souhaitant se garer
Collecter des statistiques de trafic directionnelles et multimodales (piétons, vélos, deux-roues, voitures, utilitaires, poids lourds) aux intersections pour réguler les feux tricolores de manière dynamique afin de réduire les temps de parcours et sécuriser les mobilités douces
Collecter des statistiques de trafic sur voies rapides (débits par mode, taux d’occupation et vitesse) pour pallier l’obsolescence des dispositifs en place (boucles électromagnétiques) afin d’opérer efficacement les infrastructures : information sur les temps de parcours et études fiables en vue de réaménagements
Collecter des informations permettant une tarification fiable et efficace aux péages (avec ou sans barrière) : classification de véhicules, comptage du nombre d’essieux
Détecter automatiquement des incidents de trafic (véhicule arrêté, etc.) pour sécuriser rapidement les infrastructures
Les secrets du Deep Learning
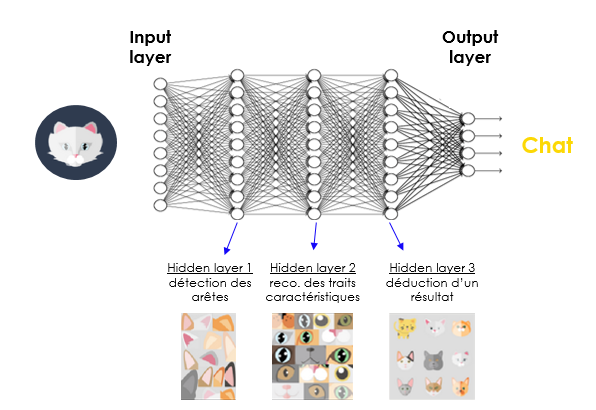
Les algorithmes de Deep Learning s’appuient sur des réseaux de neurones artificiels pour analyser des données. Les données d’input (à analyser) passent par plusieurs couches qui les décomposent pour obtenir un résultat d’analyse (output).
En informatique, et en particulier dans l’analyse d’image, il s’agit d’un véritable changement de paradigme. Le logiciel passe en effet d’un rôle de super exécutant à celui de super apprenant.
Dans le rôle traditionnel du logiciel de « super exécutant », le codeur renseigne une série de règles qui permettent aux programmes d’exécuter des suites d’opérations logiques (ex : if/ else ) pour aboutir à des conclusions différentes selon les contextes. Dans le cas de l’analyse d’images, cette technique consiste par exemple à renseigner (i) un seuil de variation de pixels à partir duquel on considère qu’il y a un mouvement sur l’image, permettant par exemple d’incrémenter un compteur dans le cas des statistiques de trafic et (ii) des seuils variables pour différencier les modes de transport selon leurs tailles moyennes (ex. camions vs. voitures). Cette approche simpliste est limitée par :
La complexité du paramétrage : la taille en pixel des objets varie selon les résolutions d’images et les prises de vue
Le manque de fiabilité : forte sensibilité aux variations de lumières et aux mouvements de la caméra
Le manque de finesse d’analyse : comment distinguer un vélo d’un deux-roues motorisé avec des règles simples ?
Dans son nouveau rôle de super apprenant, la logique est inversée : le développeur logiciel montre une grande quantité d’exemples de bons résultats aux modèles qui apprennent seuls les chemins logiques les guidant vers un résultat. Pour fonctionner, ce type de logiciel nécessite un triptyque gagnant :
Données: le logiciel a besoin d’une grande quantité d’exemples d’images d’un objet donné pour apprendre à reconnaître ce même type d’objet sur une image qu’il n’a jamais vue. A titre d’exemple, le réseau de neurones convolutif ResNet vainqueur du concours ImageNet en 2015 s’était entrainé sur 15 millions d’images.
Algorithmie: les architectures les plus performantes sont souvent les plus complexes. Le modèle FasterRCNN considéré comme détenant l’état de l’art dans la détection contient plus de 152 couches d’analyses.
Hardware: ces modèles nécessitent des ressources de calcul importantes, aussi bien pour l’entrainement que pour l’inférence (i.e. leur utilisation). L’entraînement d’une variante du FasterRCNN sur un serveur disposant de 8 cartes graphiques professionnelles (300 watts de consommation par carte) dure une semaine. En production, ce modèle a besoin d’environ 1 seconde avec une carte graphique type 2080 Ti (serveur centralisé) pour se prononcer sur une seule image.
L’Intelligence Artificielle étant une discipline où l’open source est une pratique très répandue, il n’est pas rare que des non-initiés considèrent qu’il s’agit d’une commodité. Il serait facile de s’approprier les travaux partagés par les membres de la communauté scientifique pour les appliquer sur des cas d’usages industriels : par exemple, transformer la caméra en capteur de données de mobilité.
Néanmoins, le Deep Learning présente une série d’obstacles techniques à surmonter pour concrétiser des ambitions au niveau industriel.
Le Deep Learning à l’épreuve du terrain : les limites de l’open source
Transformer la caméra en capteur de données de mobilité implique des enjeux majeurs pour chacun des composants faisant le succès du Deep Learning :
Données: tous les modèles de détection partagés par les membres de la communauté scientifique ont été entraînes sur des images de bonne qualité (pas de pixellisation, pas d’éblouissement, pas de pluie, etc.) et sont très sensibles à la qualité des images. Or, les images vidéo issues de milieu urbain sont généralement de faible qualité, ce qui rend l’application de ces modèles – en l’état – très compliquée. Par ailleurs, les bases de données d’images (qui servent à l’entrainement et aux tests des algorithmes) n’intègrent pas tous les types de véhicules et objets présents en milieu urbain (ex : pas de taxis, pas de véhicules d’urgence, pas de trottinettes, pas de poussettes, pas de fauteuils roulants, etc.).
Algorithmie: les solutions algorithmiques partagées par la communauté scientifique ne sont pas encore fiables dans le cas de flux denses de piétons ou de véhicules où les objets se masquent les uns les autres. Cela mène à la création d’identités multiples, à la non-détection d’objets ou à l’échange d’identité entre objets ce qui fausse largement les conclusions des algorithmes.
Hardware: les modèles de détection les plus performants disponibles en open source demandent de très grandes ressources de calcul, tant pour leur entrainement que pour leur exécution. Or, les utilisateurs potentiels de ces modèles ne disposent généralement ni des budgets, ni des équipements, ni des infrastructures réseaux et électriques pour utiliser ces types de matériel.
Passer à l’échelle : la valeur de l’expertise du spécialiste
Wintics met à profit son expertise en Deep Learning pour contourner ces difficultés et rendre possible l’exploitation à grande échelle des caméras pour extraire en temps réel des données précieuses de mobilité. Grâce à notre équipe d’experts fortement impliquée et nos liens étroits avec les laboratoires de recherche les plus réputés, nos efforts en R&D nous ont notamment permis d’apporter les solutions suivantes :
Données: notre pipeline dédié à la détection nous permet d’intégrer un nombre illimité d’objets en quelques heures avec une précision moyenne au moins deux fois supérieure à celle de l’open source. Surtout, nos algorithmes de détection ont été entraînés sur des images spécifiques au milieu urbain (jour et nuit, hautes et basses définitions, optiques et thermiques, etc.) pour atteindre des niveaux de détection compris entre 85% et 99% sur n’importe quelle caméra installée dans l’espace public
Algorithmie: notre Tracker (algorithme permettant de suivre un objet unique d’une image à l’autre en faisant ainsi une fonctionnalité nécessaire aux applications de comptage) est codé de toutes pièces par nos ingénieurs et entièrement adapté aux contextes urbains : sa précision est six fois plus élevée que l’open source dans les cas complexe de masquage d’objets et de trafic dense
Hardware: l’ensemble de notre code base a été optimisée, nous permettant d’atteindre une vitesse de calcul 50 fois plus rapide que l’open source et ainsi capables de tourner en edge dans des micro-boîtiers type Nvidia Jetson (dimension 11 cm max ; consommation entre 5 et 10 watts)
Wintics continue ses efforts de R&D pour faire de toutes les caméras des capteurs de données de mobilité facilement exploitables, précis et économiques. Nous travaillons notamment sur la scalabilité de notre solution, pour être en mesure de proposer le branchement de notre logiciel en quelques clics sur une interface web.
(*) l’erreur de classification des modèles est calculée en retenant la meilleure prédiction parmi les 5 plus probables exprimées par le modèle.